-
Regressions: From Linear to Ridge and Lasso
-
linear regression is fun.
Part1: Matrix Derivatives
X is a d*n matrix, which collects all the n r-dimensional inputs. W is a d*1 vector matrix, which records the value of weights. Y is a n*1 vector matrix, which collects all the n 1-dimensional outputs. Since it’s more than often that n>>d, it’s almost impossible to find the solution to
Thus, we need to change our goal to minimizing
To minimize the Loss, which is dependent on W, we need to take the derivative of Loss w.r.t W. There are TWO useful tricks in taking matrix derivatives.
The first trick is dimension analysis. All the four terms
is 1*1 and W is d*1, thus taking the derivative of each term w.r.t W will give us d*1 matrix, just as the shape of W.
The second trick is making analogues, which is pretending matrices to be numbers. With these two TRICKs, we can write out matrix derivatives easily.
For example, to compute
, we first drag out
as a constant, as it doesn’t contain W. What is left is just
.
If we degenerate W to a number, we consider
, which is obviously
. What is left is just simple adjustments (adding transposes and changing the order of matrices) according to dimension analysis. Since
, whose shape is [d*n * n*d * d*1] = [d*1]. We can get that
Thus,
. Solve for
, we get that
Part2: From Linear Fitting to Non-linear Fitting
Example: We are trying to figure out the relationship of the remained fraction of a radioactive isotope with experienced time t. Let x be a 2*1 input and y be its 1*1 output.
If we design
and y= remained fraction, training may not be able to give a good fit because we know that y is decreasing exponentially rather than linearly. In other words,
is the form of relationship that the remained fraction and time would hold.
In this case, we would naturally process data input
from
to
.
In general, if we observe that the relationship between collected data points y and x are not linear, we would process data input
to
in hope of finding some linear relationship between processed features.
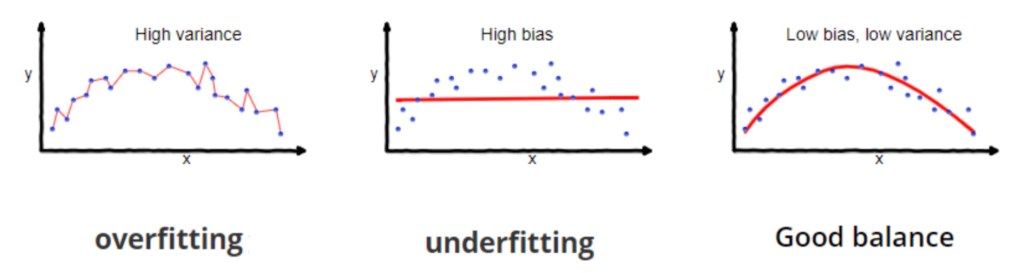
Part3: Bias & Variances TradeOFF
Consider that I answered a question wrong in an exam. There are two cases: the question is either in the mock or not. If the question is in the mock, the reason why I answered it wrong is that I didn’t pay enough attention to the mock. If the question is not in the mock, the reason why I answered it wrong is that I memorize every question in it and apply every detail of the answers to a completely different question in the exam.
Similarly, in prediction models, prediction errors can be decomposed into two main subcomponents: errors due to bias, and errors due to variance.
The machine either doesn’t study enough or study every detail from the training data. Either situation leads to a failure in the test data.To be a lazy student or a overly-diligent student? That is the question. The answer is Balance.
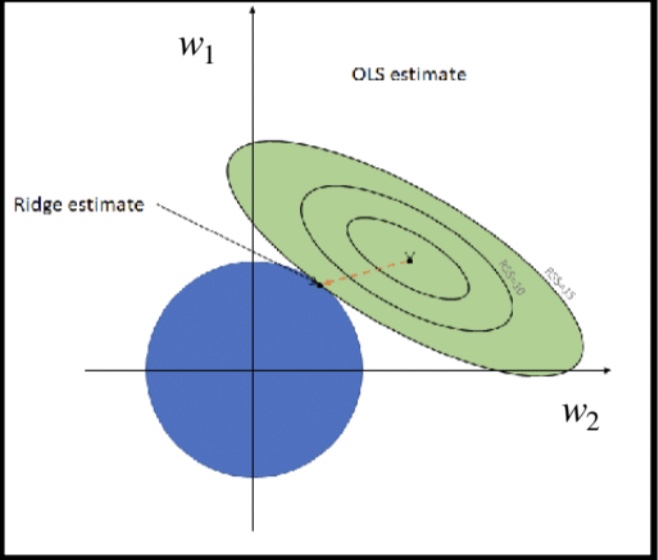
Part4: Ridge Regression
4.1 Invertibility of
In OLS, we get that
But! What if
Proof: For any non-zero d*1 vector z:
But being PSD is not enough for being invertible.
Then for what X is
Claim: X with full row rank makes
Proof:
Since X has full row rank,
has full column rank. So
is a linear combination of the independent columns of
,
. Thus for any non-zero d*1 vector z:
.
Therefore, when d>n, X can’t be full row rank. Thus
4.2
When d>n, what could we do?
is PD.
Proof:
Suppose c is an eigenvalue of
. Then we claim that
is also an eigenvalue of
. As
. Thus all the eigenvalues of
, which are positive. Thus
Therefore,
The name ‘ridge’ refers to the shape along the diagonal of I.
4.3 Loss Function of Ridge Regression
We recover the loss function by starting from the solution
.
.
.
= Loss function of Ridge Regression
= Loss function of OLS Regression +
.
Part5: Lasso Regression
5.1 Loss Function of Lasso Regression:
5.2 Compared to Ridge Regression:
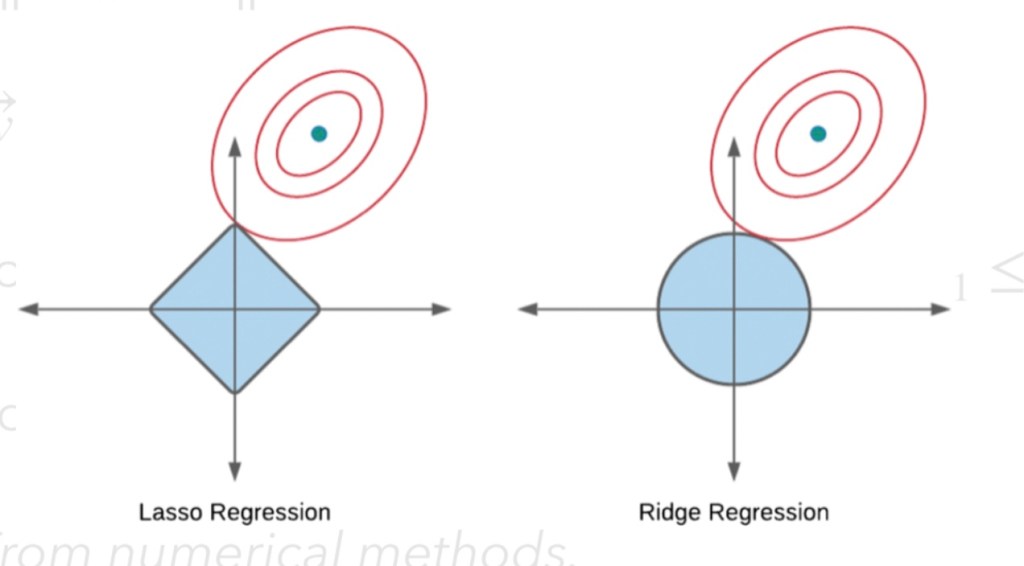
Because of diamond shape, the eclipse will often intersect it at each of the diamond corners. Due to that, at least one of the coefficients will equal zero. It serves as a method of eliminating features.
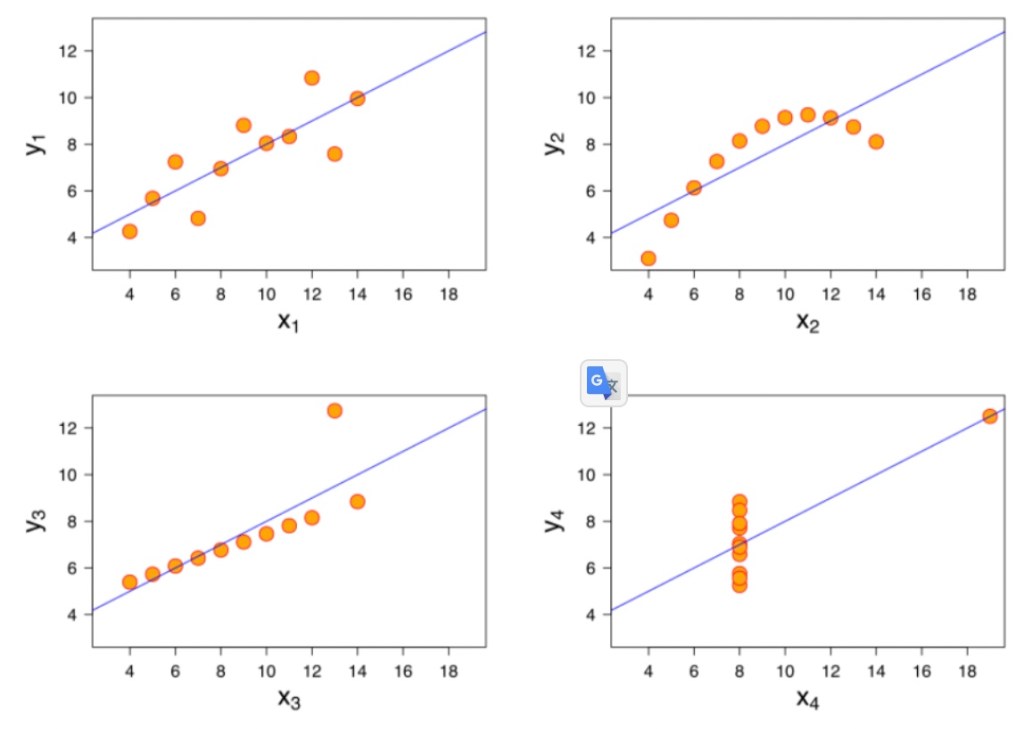
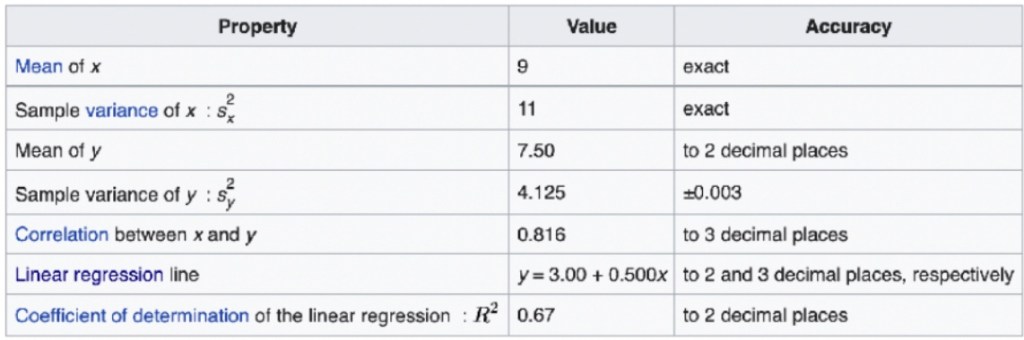
Part6: Numbers May Deceive You
A classic example of how numbers can deceive you if you don’t plot data out is Anscombe’s quartet.
Regressions: From Linear to Ridge and Lasso











